- Read Tutorial
- Watch Guide Video
We're going to see how they're related to each other and also why it's so important to understand these concepts. I can tell you from experience that overfitting is one of the major issues that can determine either failure or success of your machine learning program.
So essentially a program will suffer from overfitting when it's incapable of generalizing.

And so what that means is that imagine that you have this large data set and this could be some program such as a stock picking kind of system and you may think that if you pipe in all of the data in the world all of the historical data that you are going to then be able to make predictions in the future.
But the problem with that is many data points do not actually cause the different elements that you're looking to predict. So if you're trying to predict the sale price of a stock tomorrow and you pull in all of the different elements in the world that you could think of then you're going to run the risk of running into a logical causality err where your program is simply going to find random patterns but those random patterns in the world and in the data don't actually cause and therefore aren't good predictors for your end goal.
And so what that means is that when you perform overfitting and you're putting too much data in your system then you're not going to be able to make the right kinds of generalizations.
Remember one of the top goals of machine learning is to be able to find patterns in data and find the patterns that truly cause the end goals that you're looking for because that's how you're going to be able to make your predictions. And so the formal definition for overfitting is that it is a modeling arm which occurs when a function is too closely fit to a limited set of data points.

And so let's walk through one of my favorite examples of overfitting. And it comes from a case study where researchers were trying to find the link between wealth and happiness. And as you can see on the top three graphs they have happiness on the left hand side they have wealth there at the bottom
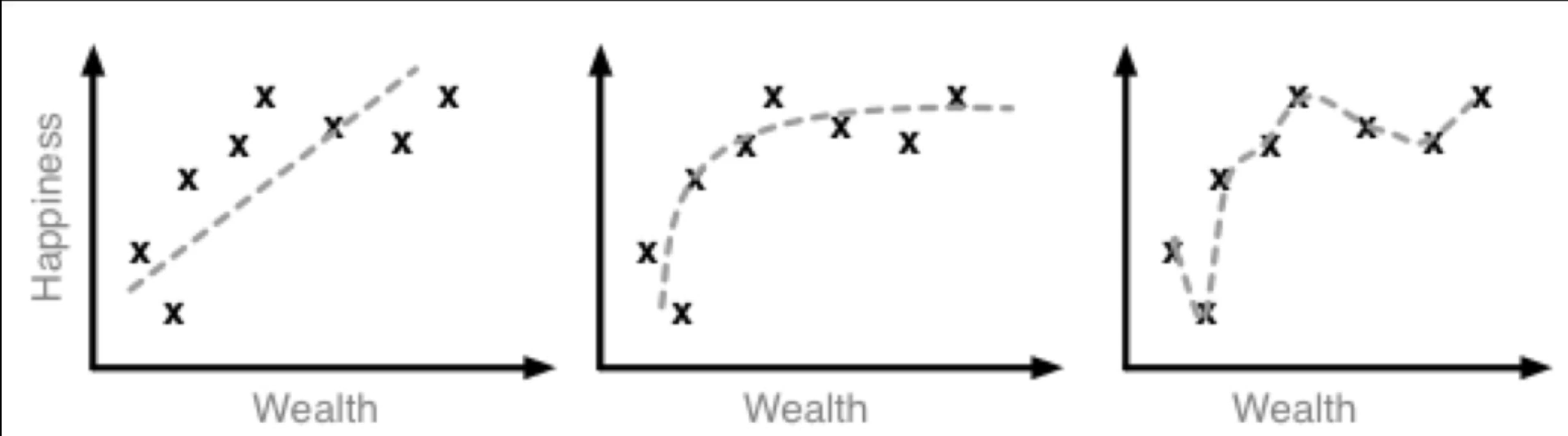
and they created three different types of machine learning algorithms that tracked historical data to try to determine what made people happy and how wealth applied to that. So on the left hand side you can see that they took a linear approach and this is a issue with many people in the world today where they think that the more money they make the happier that they're going to be.
But the data didn't actually reflect that as you can see there are many different data points there that do not fit the pattern of that linear approach. So if you're trying to build a system that will accurately predict how happy you're going to be based on how much money you make than a linear approach is really not the best way because imagine that you go and you pull in all these data points of multimillionaires who suffer from depression. Their happiness points are going to be very low on the scale but their wealth data points are going to be very high. And that doesn't match that linear approach whatsoever.
However if you go to the next example where they took a different approach where they looked and they saw okay the relation between happiness and wealth is not actually linear but it peaks out at a certain point. So you do get happier once all of your needs are taken care of and you don't have as many money issues and worries than you so your happiness does increase. But then the rate of happiness tapers off and so they took a curved approach and here what they did is they did not suffer from overfitting whatsoever but instead they created the right fit for the data.
Notice how the curve follows the line of the data then look at the right hand side the top right hand example. That one is one of the most stereotypical examples of overfitting that you can possibly have. There is literally no generalization whatsoever. All that occurred here and this isn't even true machine learning all that really occurred is a pulled in so many data points and they performed overfitting with their curve. All that the curve is really doing or all the line is doing is it's just going to every single data point.
And so what's going to happen is every time that you add more historical data then you're just going to have a jagged line you have no real generalization which means that if you run a test individual through so you know their wealth and you try to gauge their happiness level you're not really going to have any way of giving a good prediction because you don't have any generalization in less you have an identical person then you're not going to be able to give a good prediction.
But on the other hand if you take that second approach whenever you get a new data point that you want to test to see and estimate the level of happiness for someone you're going to have a much more accurate prediction because you're able to properly generalize your data. And so where ever they may fall on the graph is most likely going to be closer to the other historical items and it's going to be closer to that line and so that is a much better machine learning algorithm whereas the one on the right hand side is the perfect case study of what happens when you perform overfitting.